Persistence: Saving URL Shortenings to a Database
In my last post I deployed UrlMem - but there was one problem - if I stopped the server, all URL shortenings would disappear. So in this post I’m adding a database to fix that.
As per the expert advice of Shalini Rao I’m using PostgreSQL, as it’s relatively simple, and UrlMem only has to store long and shortened URLs.

Only a few tabs are necessary to learn this simple database system.
Using PostgreSQL Locally
The first order of business was to install PostgreSQL locally for testing. They have installation instructions here.
The next step was to figure out how to use PostgreSQL. On Ubuntu I have to prefix commands with sudo -u postgres to run them as the postgres user, but on Windows or Mac this likely isn’t the case.
First I verified that I could create databases using:
Then I ran psql with sudo -u postgres psql to open Postgres’ command-line front-end. Next I ran \list to show the available databses:
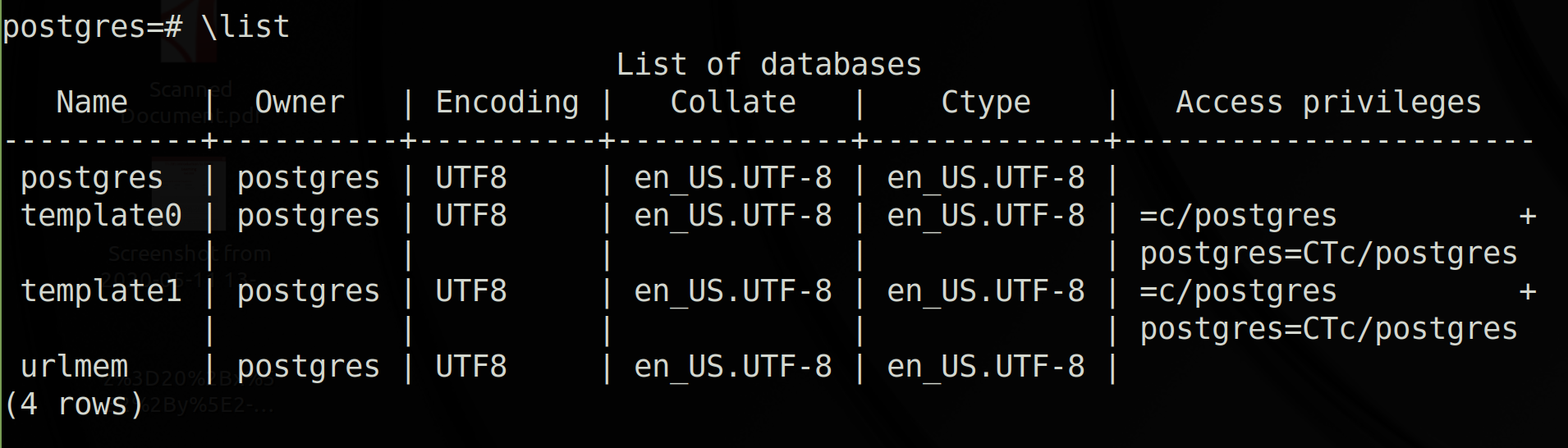
The postgres database is a default database that can be used or deleted. The database template1 is what gets copied when we create a new database, and can be customized. The template0 database can also be used for new databases, but isn’t meant to be customized.
And then there’s urlmem, the recently created database.
Creating the Table
When I ran psql I didn’t specify a database, so by default I was connected to the postgres database.
I switched to the urlmem database via \connect urlmem.
Then I created a table with this command:
This represents a table of the following form:

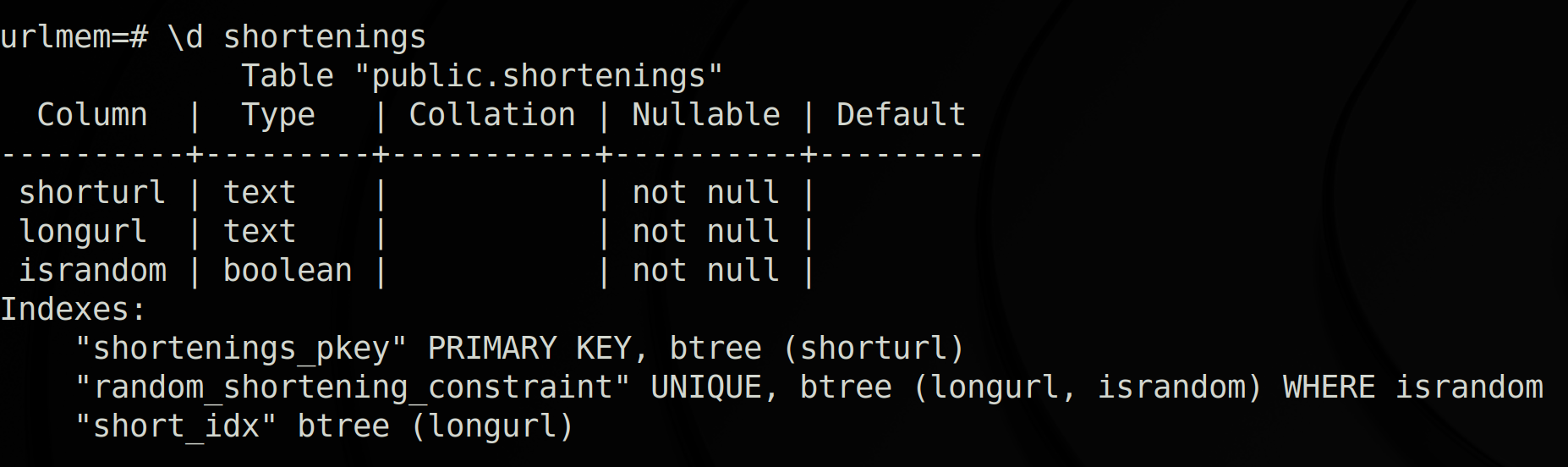
The shorturl and longurl fields are self explanatory - the israndom field tells us whether the shorturl was generated randomly or not.
The PRIMARY KEY bit enforces that the shorturl field should be non null and unique to each row. The longurl and israndom fields are also made to be non null.
Next I added a partial index on the table:
This forces the combination of longurl and israndom to be unique, but only where israndom is true. In other words, we want to set a limit of one randomly generated short URL for each long URL.
To speed things up, I also created an index on the longurl:
Indexing allows items to be retrieved quickly - this might involve using a tree structure. Since the shorturl is the primary key, it’s automatically indexed.
There’s more nuance to improving database performance, but I don’t expect performance to be an issue, so I left that alone.
To verify the table properties, I ran \d shortenings:
Creating a New User
The next step was to add a new user, as the default database user I’d been using, “postgres”, is the superuser/administrator.
While still in psql, I ran the following commands to create the user “me” with password “password”:
Note that SQL uses single quotes for strings.
Next I gave the user search and insert permissions:
I closed psql, and then logged into psql using that user:
Note that before doing so, I had to change the following line in /etc/postgresql/12/main/pg_hba.conf:
to the following:
This is because with the peer setting, psql uses the terminal user’s username to authenticate, instead of asking for a password. This might not apply to all installations.
The last step to the setup was to test the granted permissions by inserting some values into the table, and then displaying the table:
Setting up PostgreSQL for Node
To setup PostgreSQL for node, I ran npm install --save pg from the project directory. Then I created a new file queries.js.
Here is what the setup in queries.js looks like:
Another way to set things up is to use Client instead of Pool. Pool is more efficient though - it sets up a group of clients. That way, multiple queries to the database can execute in parallel using different client instances.
Sending Queries in Node
In queries.js I have four functions - isShortUrlUsed, getLongUrl, getRandomShortening, and addShortening. Here I’ll explain addShortening, as it’s the most interesting one:
This function tries to add a shortening, but returns null if there is a uniqueness constraint error. The first constraint, ‘shortenings_pkey’, is for trying to use a shorturl twice, and the second constraint is for adding two random shortenings for one long URL.
The other interesting code in this function is the use of async and await.
In javascript often we have functions that return immediately, but dont complete their tasks immediately - such as setting a timer:
These functions are considered asynchronous. Database queries are also considered asynchronous. If we want to do something after a database query completes, we have to use the .then(function) syntax:
Having a bunch of .then()s can become messy - which is where async functions come into play. By marking a function as async, it becomes asynchronous - but we’re also able to use await inside of it.
The await keyword simply waits for an asynchronous function to finish before continuing, removing the need to chain a bunch of calls to .then().
You can find my code up to this point here, with some minor differences.
Moving things to Heroku
The next step was setting up PostgreSQL on Heroku. Heroku has instructions for doing so here.
After setting up a databse, I ran heroku pg:psql and then created the table/indices from earlier.
One small change I had to make was to pooling - it isn’t supported for free users of Heroku so I switched to using Client, which is documented here.
But aside from that, things worked as well as they had locally.
What’s Next
Last post, I talked about potentially filtering for bad words that get randomly generated. Recently, I’ve also had the idea of making a UrlMem extension, so that people can right click a link, and get a shortened version from there. Another idea is to let allow user accounts, so that people can create shortenings without conflict.
Out of these ideas, I think I’ll probably make an extension - but after that, I might be done - I’m pretty happy with UrlMem as it stands.
Until next time!
Sources
PostgreSQL on Ubuntu
PostgreSQL 12.3 Documentation
How to List Databases and Tables in PostgreSQL Using PSQL
PostgreSQL CHAR VARCHAR TEXT
How to Switch Databses in PSQL
How to Get the Name of the Current Database from within PostgreSQL
Show Tables in PostgreSQL
Peer Authentication Failed Postgres
PostgreSQL Describe Table
PostgreSQL insert
PostgreSQL How to Grant Access to Users
PostgreSQL Unique Constraint
PostgreSQL Boolean
Heroku PostgreSQL
Node assert
Async Await Javascript
Async Await
Setting up a Restful API with NodeJs and PostgreSQL
Node Postgres
| Back to Project |
Get occasional project updates!
Get occasional project updates!